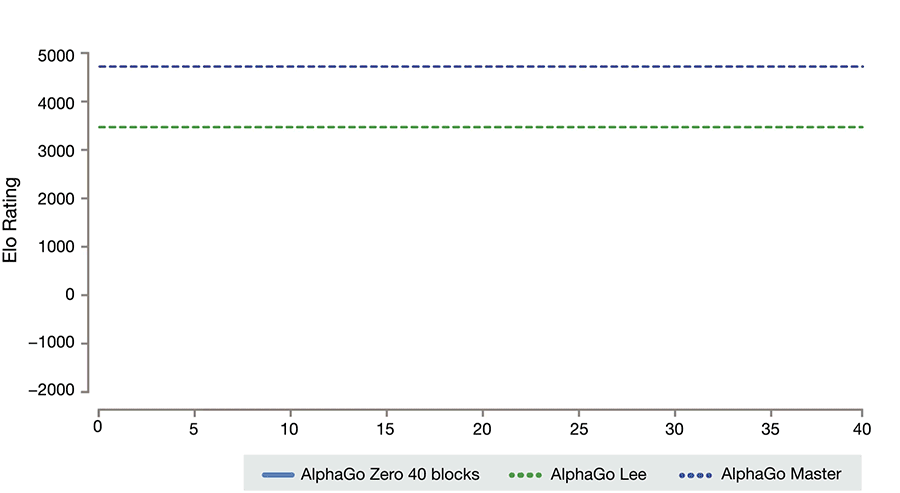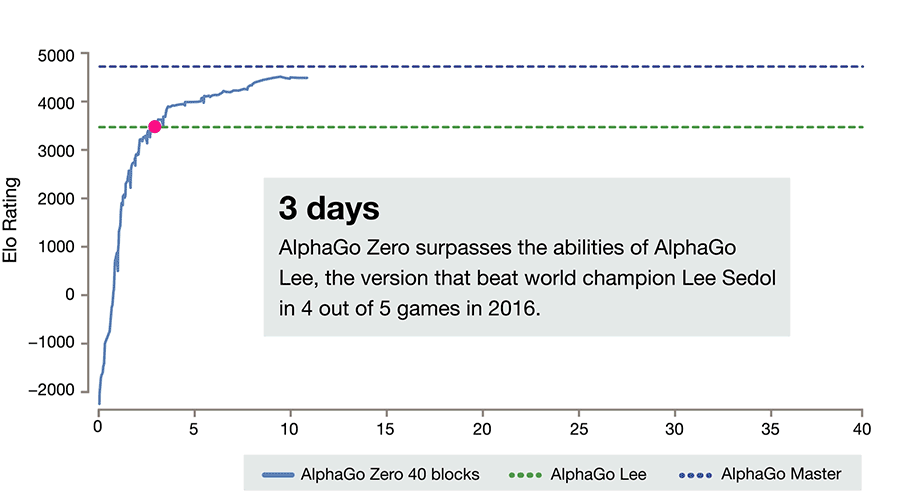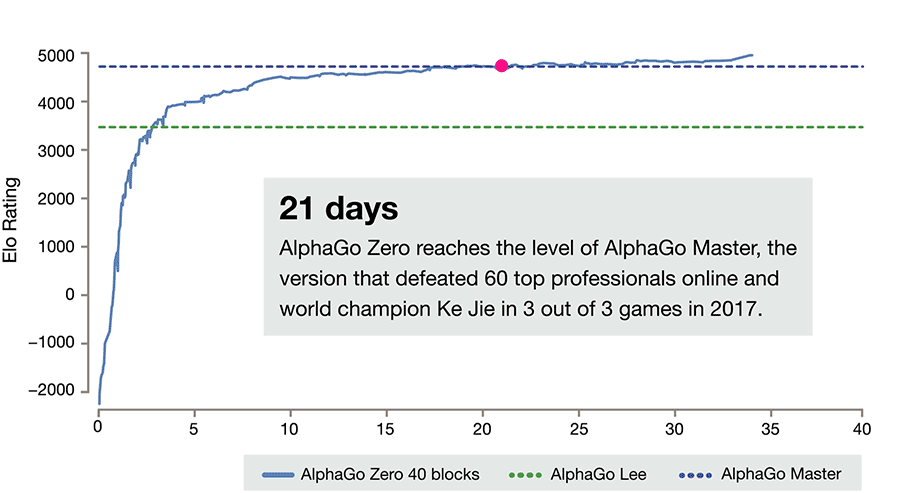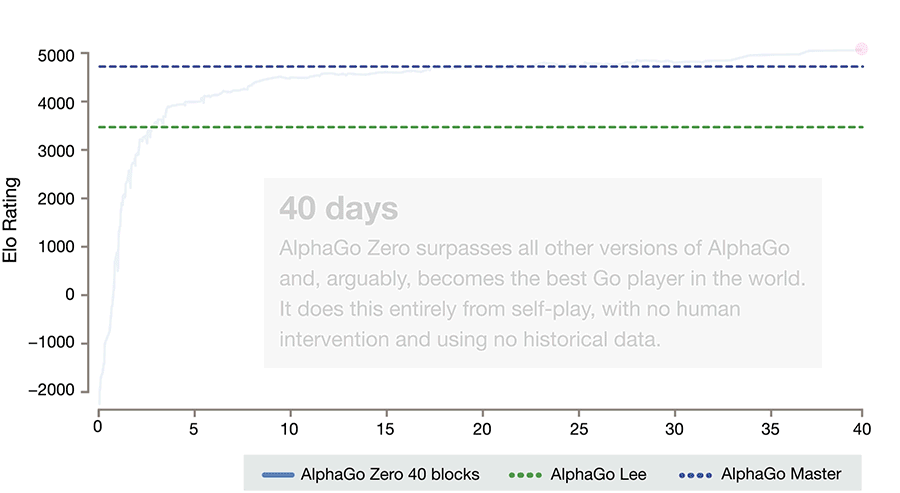
If you follow artificial intelligence research, you probably saw last week's Nature article on DeepMind's AlphaGo Zero. The latest version of its Go-playing AI, AlphaGo Zero used no human data, learned the game strictly by playing against itself, achieved master-level play in 4 days, and beat its previous incarnation—which learned from human data—100-0.
This breakthrough has implications beyond Go and AI research. In particular, if you're reading this blog, you may wonder, as I did, the implications for biomedical research in general, and artificial intelligence drug discovery in particular.
To investigate, I discussed this internally with our machine learning and bioinformatics teams, and externally with friends and advisors who work in the field. They confirmed: This is big. But there are important caveats.
Image 1: AlphaGo Zero improvement over 40 days (credit: DeepMind)
The Problem With Human-Curated Datasets
To understand why this is big, let's do a quick refresh on neural networks.
To date, most neural networks require massive, usually human-curated datasets to learn anything. "If you only have ten examples of something, it’s going to be hard to make deep learning work," noted Jeff Dean, a senior fellow at Google and head of the Google Brain project, at a recent conference. "If you have 100,000 things you care about, records or whatever, that’s the kind of scale where you should really start thinking about these kinds of techniques."
If you want a neural network to recognize a dog in a picture, for example, you must show it many pictures of dogs with the label "dog." It will then tweak itself through an iterative process until it accurately predicts "dog" when shown images with canines. (This is a massive oversimplification, of course. Here's a quick video primer on neural networks if you're interested.)
This works great with classification problems, but works less great with more complex challenges, and with challenges for which we have less human-curated data. If you want to train a neural network to drive, for example, you need terabytes of driving data to teach it. And even then, the odds that this data would contain every possible scenario is unlikely.
There are similar challenges in biomedical applications such as designing drugs for drug targets, predicting protein folding, and predicting drug effects, side effects and interactions. Since human-curated databases for such problems are limited—that's why we want to use AI in the first place!—AI has little to learn from.
For such challenges, it would therefore be better if AI could learn by itself and devise its own strategies to solve problems rather than rely on limited datasets.
Overcoming Data Scarcity With Reinforcement Learning
This is the promise that AlphaGo Zero represents. While previous versions learned from thousands of human amateur and professional games, AlphaGo Zero taught itself to play by receiving only the goal (win), the rules, and feedback on its success. It then made random moves, learned which resulted in positive rewards, and continued from there. And it did so quite efficiently, using just 4 specialized processing units—44 times fewer than the original AlphaGo, which used 176.
Image 2: Improvements in AlphaGo efficiency as indicated by number of Tensor Processing Units (TPUs) (Credit: DeepMind)
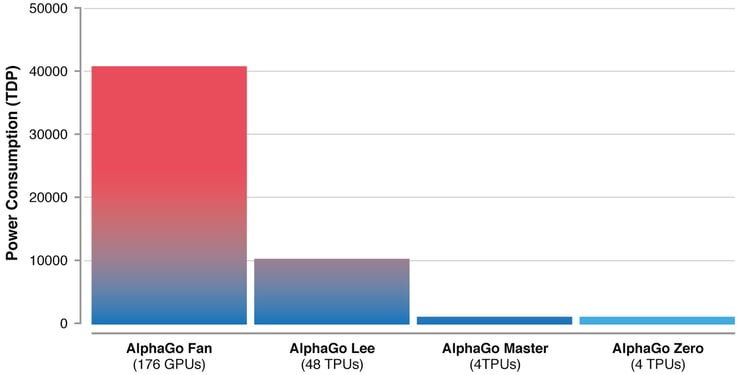
The results demonstrate the potential of an approach called reinforcement learning. A simple example of reinforcement learning is giving a dog a treat when it sits on command; this provides positive feedback that reinforces the behavior. Similarly, using reinforcement learning, we can program machines to optimize their behavior in a way that maximizes rewards. In so doing, they can effectively produce the data they need to learn, rather than rely on existing datasets. And because they're not reliant on existing datasets, they're not constrained by those datasets.
"AlphaGo is not tethered to human performance anymore," says David Q. Chen, BenchSci's CTO. "It began by training on human data before. So its foundation was human performance. If that foundation was weak, AlphaGo would be forever suboptimal. So, to continue improving AlphaGo, they had to transcend the need for human datasets. Using reinforcement learning to do so, in this case, makes sense, as the game of Go has clear goals, rules and reward signals against which machine learning can optimize."
Potential Applications (and Limitations) in Biomedicine
This approach can also be applied to biomedical research and drug discovery.
We could, for example, give an AI the goal of designing a drug for a specific target and the rules of chemistry, then let it come up with novel compounds. In fact, researchers are already working on this. Similarly, we could give AI the goal of solving protein folding problems, which researchers are also working on, and which DeepMind has explicitly called out as being amenable to their approach with AlphaGo Zero.
There could also be direct clinical applications.
"The reinforcement learning model is an approach that is free from training datasets," says Mohamed Helmy, Head of Bioinformatics at BenchSci. "Such success can open new avenues in personalized medicine. Instead of determining the treatment (e.g. drug dosage or radiotherapy sessions) based on data from 'other' patients, reinforcement learning models could learn from the same patient's data and determine a treatment that fits this particular patient's condition. This can impact patients with chronic diseases such as diabetes and renal failure where a continuous regulation of specific blood markers (sugar and hemoglobin, respectively) is required."
Chen warns, however, that reinforcement learning might not be broadly applicable beyond applications where there are immediate reward signals. For this reason, he points out, most reinforcement learning today is done in video games or robots.
Even so, he notes, AlphaGo Zero is an important advance. "It probably means that given a fast enough feedback cycle, it can learn anything and beat a human at it in about a month."
And if that expedites biomedical research and drug discovery, everybody wins.

Go board image credit: Donar Reiskoffer, Wikimedia
